Agenta vs OpenMark AI
Side-by-side comparison to help you choose the right AI tool.
Agenta is the open-source LLMOps platform that transforms AI development with centralized collaboration and robust.
Last updated: February 28, 2026
OpenMark AI instantly benchmarks over 100 LLMs on your exact task for cost, speed, and quality with no setup or API keys.
Last updated: March 26, 2026
Visual Comparison
Agenta
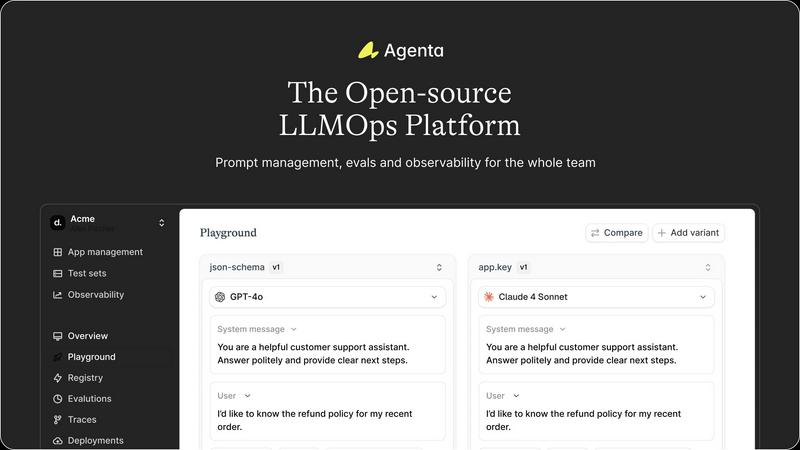
OpenMark AI

Feature Comparison
Agenta
Centralized Prompt Management
Agenta offers a centralized platform where prompts, evaluations, and traces are stored and managed, streamlining workflows for the entire team. This feature eliminates the chaos of scattered documentation and ensures that all team members have access to the same resources, enhancing collaboration and minimizing misunderstandings.
Automated Evaluation
Agenta replaces guesswork with a systematic approach to running experiments and tracking results. Automated evaluation allows teams to validate changes based on real evidence, fostering a culture of data-driven decision-making. This feature supports integration with various evaluators, ensuring flexibility and adaptability to different development needs.
Unified Playground
The unified playground feature allows teams to compare prompts and models side-by-side, facilitating quick iterations and improvements. It includes a complete version history, enabling teams to track changes over time and providing the ability to test different models without being locked into a single provider.
Trace Annotation and Debugging
Agenta enables teams to trace every request and identify exact failure points in their AI systems. With the ability to annotate traces collaboratively, teams can gather feedback from both users and experts. This feature closes the feedback loop by allowing any trace to be turned into a test with a single click, significantly enhancing debugging efficiency.
OpenMark AI
Plain Language Task Orchestration
Describe the exact AI task you need to benchmark using simple, intuitive language—no complex coding or prompt engineering required. The platform's intelligent system interprets your intent, whether it's data extraction, creative writing, classification, or complex agentic reasoning, and structures the benchmark accordingly. This human-centric interface ensures you're testing what you actually intend to build, bridging the gap between concept and empirical validation with unprecedented ease.
Multi-Model Concurrent Benchmarking
Execute your defined task against a massive, ever-growing catalog of 100+ frontier and specialized LLMs simultaneously in one session. This parallel testing architecture delivers side-by-side results in minutes, not days, providing a direct, apples-to-apples comparison. You see every model's response to the identical prompt under identical conditions, powered by real API calls to ensure you're reviewing genuine performance data, not cached or synthetic marketing numbers.
Holistic Performance Intelligence Dashboard
Move beyond simple accuracy with a multi-dimensional analysis of model performance. The dashboard presents a synthesized view of scored output quality, real API cost per request, latency, and critical stability metrics across multiple repeat runs. This holistic intelligence allows you to balance trade-offs between speed, cost, and reliability, making truly informed decisions based on the complete operational picture of each model.
Variance & Stability Scoring
OpenMark AI doesn't just run a test once; it analyzes consistency. By executing the same task multiple times, the platform calculates and displays performance variance, showing you which models deliver stable, predictable outputs and which produce erratic, "lucky" results. This focus on statistical reliability is essential for deploying production-grade AI features where consistency is as important as peak capability.
Use Cases
Agenta
Rapid Prototyping of AI Applications
Agenta is ideal for teams looking to rapidly prototype AI applications. By centralizing workflows and providing tools for evaluation and collaboration, developers can quickly iterate on prompts and models, significantly speeding up the development cycle.
Performance Monitoring and Improvement
With Agenta's robust observability features, teams can monitor the performance of their AI applications in real-time. This capability allows for immediate detection of regressions and performance issues, enabling teams to respond quickly and maintain high reliability in production environments.
Collaborative Development Across Teams
Agenta fosters collaboration among product managers, developers, and domain experts by creating a unified workflow. This ensures that all stakeholders can contribute to the development process, enhancing the quality of LLM applications through diverse insights and expertise.
Evidence-Based Decision Making
Agenta empowers teams to replace intuition with evidence in their decision-making processes. By utilizing automated evaluations and comprehensive performance tracking, teams can make informed choices that lead to better outcomes and more reliable AI applications.
OpenMark AI
Pre-Deployment Model Validation for Product Teams
Before integrating an LLM into a live application, product teams can use OpenMark AI to empirically validate which model delivers the required quality for their specific feature—be it a customer support chatbot, a content summarizer, or a code assistant. This eliminates costly post-launch pivots by ensuring the chosen model performs reliably and cost-effectively on the exact tasks it will handle, de-risking the entire deployment cycle.
Cost-Efficiency Optimization for Developers
Developers focused on building scalable, sustainable applications leverage OpenMark to find the optimal balance between performance and expense. By benchmarking models on their actual tasks, they can identify the most cost-efficient option—the model that provides the necessary quality at the lowest operational cost—moving beyond theoretical token prices to understand the true economics of their AI implementation.
AI Feature Prototyping and Research
Researchers and innovators prototyping new AI-powered workflows use the platform to rapidly test hypotheses across the model landscape. By quickly iterating through different models and prompts for tasks like complex data extraction, multi-step reasoning, or image analysis, they can discover unexpected capabilities and identify the most suitable foundation for their experimental projects without infrastructure overhead.
Performance Auditing and Vendor Selection
When evaluating different AI providers or considering a model switch, engineering leads conduct systematic audits with OpenMark AI. They can benchmark incumbent models against new challengers on a battery of representative tasks, creating a data-driven dossier for vendor selection that is based on measurable, task-specific performance rather than generic benchmarks or sales claims.
Overview
About Agenta
Agenta is the revolutionary open-source LLMOps platform that serves as the foundational operating system for the era of intelligent applications. Engineered for dynamic AI development, Agenta transforms the chaotic landscape of building large language model applications into a structured, high-velocity science. It is meticulously designed for pioneering AI teams, including developers, product managers, and domain experts, who are committed to delivering reliable, production-grade LLM applications that transcend mere prototypes. By addressing the inherent unpredictability of large language models, Agenta eliminates friction caused by disparate communication silos, ineffective testing methods, and opaque debugging processes. With Agenta, teams gain a single source of truth for the entire LLM lifecycle, enabling them to experiment with precision, evaluate with evidence, and observe with clarity. This platform empowers collaboration, fosters innovation, and establishes a paradigm shift towards structured, evidence-based LLMOps.
About OpenMark AI
OpenMark AI is the definitive, no-compromise platform for task-level LLM benchmarking, engineered to eliminate the guesswork from AI model selection. It is a revolutionary web application that allows developers and product teams to describe their specific AI task in plain language and then execute that exact prompt against a vast catalog of over 100+ leading models in a single, unified session. The platform delivers a comprehensive performance matrix, comparing critical real-world metrics like cost per request, latency, scored output quality, and—crucially—stability across repeat runs. This reveals performance variance, exposing inconsistent "lucky" outputs rather than presenting a single, potentially misleading result. Built for the pre-deployment phase, OpenMark AI provides the empirical data needed to ship AI features with confidence, ensuring you select the optimal model for your workflow based on actual cost efficiency and reliable performance, not just marketing datasheets. It operates on a hosted credit system, removing the friction of configuring and managing separate API keys for OpenAI, Anthropic, Google, and other providers for every comparison. This is performance intelligence, distilled.
Frequently Asked Questions
Agenta FAQ
What is LLMOps?
LLMOps refers to the operational practices and tools used in the development and management of large language models. It encompasses processes for experimentation, evaluation, deployment, and monitoring of AI applications.
How does Agenta help in debugging AI systems?
Agenta provides detailed tracing of requests and allows for collaborative annotation of those traces. This enables teams to identify failure points accurately and turn any trace into a test, significantly streamlining the debugging process.
Is Agenta suitable for teams new to AI development?
Absolutely. Agenta is designed for both seasoned AI teams and those just starting out. Its user-friendly interface and comprehensive documentation make it accessible for teams at any stage of their AI development journey.
Can Agenta integrate with existing tech stacks?
Yes, Agenta seamlessly integrates with various frameworks and models, including LangChain and OpenAI. This flexibility allows teams to incorporate Agenta into their existing workflows without disruption.
OpenMark AI FAQ
How does OpenMark AI calculate the quality score for model outputs?
The quality score is determined by evaluating model outputs against the specific success criteria of your defined task. For objective tasks (e.g., extraction, classification), it uses automated checks for accuracy and completeness. For subjective or creative tasks, it can employ a combination of heuristic analysis and, where applicable, judge models against each other or a baseline. The system is designed to quantify how well each model fulfills the intent of your prompt.
Do I need my own API keys to run benchmarks?
No. OpenMark AI operates on a hosted credit system. You purchase credits and the platform manages all API calls to the supported model providers (OpenAI, Anthropic, Google, etc.) on your behalf. This removes the significant setup friction of creating multiple accounts, managing keys, and dealing with individual billing systems, allowing you to focus purely on comparative analysis.
What does "stability" or "variance" mean in the results?
Stability refers to how consistent a model's performance is across multiple runs of the identical task. A model with low variance will produce very similar outputs (in quality, structure, and content) each time, which is critical for production systems. High variance indicates unpredictability—sometimes it gives a great answer, sometimes a poor one. OpenMark AI runs your task multiple times to surface this metric, so you can avoid models that are unreliable.
Can I test private or fine-tuned models on OpenMark AI?
Currently, OpenMark AI focuses on providing benchmarking for its extensive catalog of publicly available, hosted foundation and frontier models from major providers. This ensures standardized, comparable access for all users. Support for testing privately fine-tuned or custom models is a potential area for future development as the platform evolves.
Alternatives
Agenta Alternatives
Agenta is an open-source LLMOps platform designed to revolutionize the development and management of AI applications collaboratively. As a foundational operating system for intelligent applications, it addresses the chaotic nature of AI development, enabling teams of developers, product managers, and domain experts to create reliable, production-grade LLM applications. Users often seek alternatives to Agenta due to various factors, including pricing structures, specific feature sets, or the need for compatibility with existing platforms. When choosing an alternative, it is essential to evaluate the platform's ability to provide a cohesive infrastructure for collaboration, experimentation, and continuous improvement of AI systems, ensuring that it meets the unique demands of your team.
OpenMark AI Alternatives
OpenMark AI is a next-generation, task-level LLM benchmarking platform in the developer tools category. It revolutionizes pre-deployment validation by running your specific prompts against a vast catalog of models in a single session, delivering real-world metrics on cost, latency, scored quality, and output stability. Users often explore alternatives for various reasons, including budget constraints, specific feature requirements like on-premise deployment, or the need for deeper integration into existing CI/CD pipelines. The landscape of AI evaluation tools is rapidly evolving, with new solutions emerging to address different facets of model testing and observability. When evaluating an alternative, prioritize platforms that provide genuine, uncached API call results, measure real-world cost efficiency beyond token price, and quantify output variance across multiple runs. The ideal tool should align with your workflow, offering actionable intelligence to de-risk your AI feature launches with empirical data, not just marketing benchmarks.